In Nederland is al enige tijd sprake van een woningtekort, resulterend in almaar stijgende huizenprijzen. Een overspannen woningmarkt zorgt ervoor dat starters moeilijk aan een huurwoning komen, laat staan een koopwoning. De gemiddelde transactieprijs van een koopwoning was in 2023 ruim € 416.000,-.1 In datzelfde jaar lag het bruto modaal inkomen (het inkomen dat onder de bevolking het vaakst voorkomt) voor huishoudens op zo’n € 41.500,-.2 Tegen het einde van 2025 kon iemand van dertig jaar oud zonder partner voor dit salaris een hypotheek van bijna twee ton afsluiten.3 Dit zou betekenen dat hij/zij meer dan tweehonderdduizend euro aan eigen geld moest inleggen, een bedrag dat de meeste mensen niet op de plank hebben liggen!
Uiteraard is de huizenprijs afhankelijk van de regio: uitgaande van identieke oppervlakten ligt in dichtbevolkte gebieden de prijs van een huis hoger dan in dunbevolkte gebieden. Datzelfde geldt voor iemands salaris: in gebieden met veel economische activiteit ligt het loon hoger dan in gebieden met weinig economische activiteit. Een opsomming van deze twee variabelen is deels te zien in tabel 1. (In dit artikel spreken we van “regio”, wat feitelijk gebaseerd is op “COROP-gebied”, een regionaal niveau tussen gemeenten en provincies in. Nederland telt veertig COROP-gebieden.4) De volledige set van gegevens is grafisch weergegeven in figuur 1. Deze informatie kun je ook hier downloaden. Hiermee weten we hoe deze variabelen zich afzonderlijk van elkaar “gedragen”, maar weten we nog niet hoe zij zich verhouden tot elkaar.
| Nr. | Regio | Inkomen (€) | Huizenprijs (€) |
| 1. | Oost-Groningen | 47.600 | 240.000 |
| 2. | Delfzijl en omgeving | 47.100 | 213.000 |
| 3. | Overig Groningen | 48.600 | 283.000 |
| \(\vdots\) | \(\vdots\) | \(\vdots\) | \(\vdots\) |
| 38. | Midden-Limburg | 54.300 | 315.000 |
| 39. | Zuid-Limburg | 49.200 | 266.000 |
| 40. | Flevoland | 56.100 | 347.000 |
| Tabel 1. Gemiddelde inkomens en gemiddelde huizenprijzen in 2023. Bron: StatLine, CBS |
|||
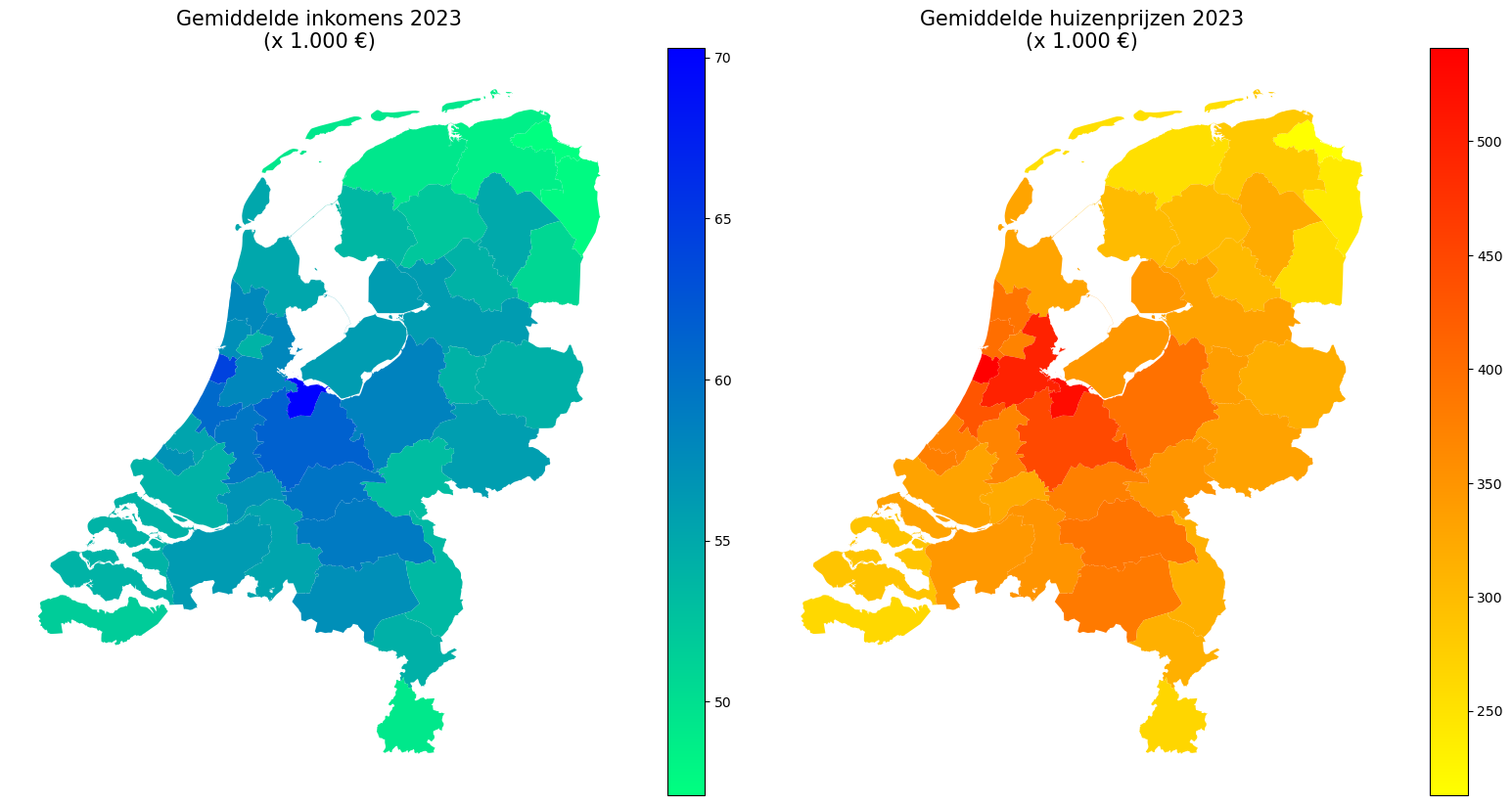
Figuur 1. Hittekaarten van de variabelen inkomen (links) en huizenprijs (rechts), conform tabel 1.
Nu de gegevens letterlijk in kaart zijn gebracht, roept dit de onvermijdelijke vraag op wat het verband is tussen inkomens en huizenprijzen. In wetenschappelijke termen spreekt men van correlatie.5 Het doel van correlationeel onderzoek is om aan te tonen dat twee variabelen (soms “grootheden” genoemd) met elkaar samenhangen. De correlatie meet en beschrijft die samenhang aan de hand van een sterkte (0 t/m 1) en oriëntatie (+/-); ze wordt uitgedrukt in een getal tussen -1 en 1. Een waarde van -1 betekent een perfecte negatieve lineaire samenhang: x stijgt met een bepaalde eenheid, y daalt in dezelfde verhouding. Bijvoorbeeld: je studietijd verdubbelt, waardoor het aantal fouten op je tentamen halveert. Een waarde van 0 duidt op het ontbreken van een lineair verband: verandering van x heeft geen invloed op y. Een waarde van 1 betekent een perfecte positieve lineaire samenhang: x stijgt met een bepaalde eenheid, y stijgt in dezelfde verhouding. Bijvoorbeeld: tijdens het vullen van een duikfles verdubbelt de hoeveelheid zuurstof, waardoor de druk in de duikfles verdubbelt.
Dit getal, dat de correlatie in een numerieke waarde uitdrukt, werd voor het eerst gepubliceerd in 1895. Het staat bekend als de Pearson correlatiecoëfficiënt (r), vernoemd naar Karl Pearson, die onder andere de chi-kwadraattoets heeft bedacht. In tegenstelling tot de chi-kwadraattoets, die categorische variabelen analyseert, geeft de correlatie de samenhang weer tussen kwantitatieve variabelen. Bij beide analyses gaat het echter om twee variabelen die elkaar al dan niet beïnvloeden. Een andere vorm van correlatie, waar we niet verder op zullen ingaan, is de Spearman rank correlation (rS), die toegepast wordt op gerangschikte data.
Door de datapunten uit te zetten in een spreidingsdiagram (synoniem voor scatterplot, of in sommige bronnen strooidiagram), met op de x-as de ene variabele en op de y-as de andere variabele, wordt de correlatie inzichtelijk gemaakt (zie figuur 2). Daarnaast kunnen door visuele inspectie extreme waardes, uitbijters (outliers), snel gedetecteerd worden. De correlatiecoëfficiënt geeft aan in welke mate de datapunten bij een rechte lijn in de buurt liggen. Een voorbeeld van een positieve correlatie is die tussen lengte en gewicht: hoe langer iemand is, des te meer deze persoon weegt, en vice versa. In figuur 2 zou dat een subplot uit de onderste rij kunnen zijn (0,5 ≤ r ≤ 1). Een voorbeeld van een negatieve correlatie is die tussen nachtrust en vermoeidheid: hoe meer uren je ’s nachts slaapt, des te minder moe je jezelf overdag voelt. Ook hier is het omgekeerde waar. In figuur 2 zou dat een subplot uit de bovenste rij kunnen zijn (-1 ≤ r ≤ -0,5).
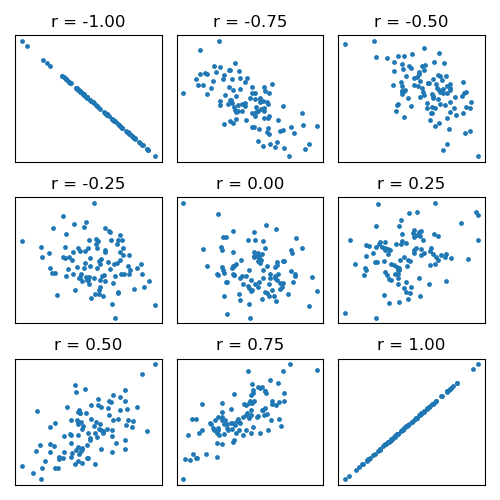
Figuur 2. Spreidingsdiagrammen voor steekproefgroottes van honderd (n = 100) met verschillende correlatiecoëfficiënten, vermeld in wetenschappelijke notatie, oftewel een punt i.p.v. een komma als decimaalteken. Iedere blauwe stip vertegenwoordigt één datapunt.
Voor het “vertalen” van de correlatiecoëfficiënt naar de kracht van de samenhang wordt de richtlijn uit tabel 2 gehanteerd.6 Kanttekening hierbij is dat wat in de ene discipline (bijv. psychologie) als sterke samenhang zou kunnen worden beschouwd in de andere discipline (bijv. natuurkunde) als zwakke samenhang zou kunnen worden beschouwd. Uit complexe systemen, waar groepen mensen toe behoren, zijn verbanden lastiger te abstraheren dan uit experimenten die verricht worden in een minutieuze laboratoriumsetting, waaronder de Large Hadron Collider (LHC) in Genève. Tevens speelt de steekproefgrootte een rol: een hoge correlatiecoëfficiënt in een kleine steekproef is nietszeggend, terwijl diezelfde correlatiecoëfficiënt in een grotere steekproef betrouwbaarder is. In de literatuur wordt een minimum steekproefgrootte variërend van 20 tot 30 datapunten geadviseerd.
| Correlatiecoëfficiënt | Kracht van samenhang |
| \(0\le\left|r\right|<0,2\) | zeer zwak |
| \(0,2\le\left|r\right|<0,4\) | zwak |
| \(0,4\le\left|r\right|<0,6\) | middelmatig |
| \(0,6\le\left|r\right|<0,8\) | sterk |
| \(0,8\le\left|r\right|\le1\) | zeer sterk |
| Tabel 2. Leidraad voor de interpretatie van de correlatiecoëfficiënt. De verticale strepen om de r zijn absoluutstrepen. Zij zetten een negatieve waarde om naar een positieve waarde. Bijvoorbeeld: |-0,3| = 0,3, een zwakke samenhang. Een positieve waarde tussen absoluutstrepen blijft ongewijzigd. | |
Het is van belang om in deze context onderscheid te maken tussen de correlatiecoëfficiënt van een populatie, aangeduid met ρ (de Griekse letter “rho”), tegenover de correlatiecoëfficiënt van een steekproef (in het Engels sample), die we reeds hebben aangeduid met r. In de praktijk hebben onderzoekers doorgaans geen toegang tot data van de gehele populatie. Daarom wordt een (in sommige gevallen herhaalde) steekproef getrokken om te kunnen generaliseren naar de populatie. Voor de berekening van de correlatiecoëfficiënt maakt het wiskundig gezien nauwelijks verschil of we te maken hebben met een populatie of een steekproef. Ofschoon erover valt te twisten, gaan we er in dit artikel van uit dat onze dataset een steekproef betreft en geen populatie. We hebben immers geen kennis van de huizenprijzen en inkomens in de rest van de wereld.
Om de statistische significantie van de correlatiecoëfficiënt r te testen wordt een t-toets gebruikt. De nulhypothese stelt dat r gelijk is aan nul, de alternatieve hypothese stelt dat r niet gelijk is aan nul. Er wordt aangenomen dat het verband tussen de grootheden lineair is – dus niet exponentieel – en dat beide grootheden normaal verdeeld zijn – dus niet scheef. In het geval dat het resultaat significant is en de nulhypothese wordt verworpen, is de conclusie dat er een lineair verband bestaat tussen de grootheden.
Voor een set van gepaarde getallen (x1, y1), (x2, y2), … (xn, yn), wordt de correlatiecoëfficiënt als volgt berekend:\[r=\frac{\sum_{i=1}^{n}{(x_i-\bar{x})(y_i-\bar{y})}}{\sqrt{\sum_{i=1}^{n}{(x_i-\bar{x})}^2\sum_{i=1}^{n}{(y_i-\bar{y})}^2}}\]In deze formule is Σ (de Griekse letter “sigma”) het sommatieteken, n de steekproefgrootte, i het indexnummer en 2 in superscript het kwadraatteken. Het deel in de teller wordt ook wel de covariantie genoemd, die aangeeft in welke mate twee variabelen samen bewegen. Om de formule toe te passen op de probleemstelling waarmee dit artikel begon, het verband tussen inkomens en huizenprijzen, is n het aantal regio’s, namelijk 40. xi is het gemiddelde inkomen in de betreffende regio en x̅ het gemiddelde inkomen van alle regio’s, namelijk € 55.475,-. yi is de gemiddelde huizenprijs in de betreffende regio en y̅ de gemiddelde huizenprijs van alle regio’s, namelijk € 347.375,-. Vervolgens is het een kwestie van de getallen invoeren teneinde de correlatiecoëfficiënt te berekenen:\[r=\frac{(47.600-55.475)\times(240.000-347.375)\ldots+(56.100-55.475)\times(347.000-347.375)}{\sqrt{\left[{(47.600-55.475)}^2\ldots+{(56.100-55.475)}^2\right]\times\left[{(240.000-347.375)}^2\ldots+{(347.000-347.375)}^2\right]}}\approx0,91\](Omwille van ruimtegebrek zijn alleen de waardes van de eerste en laatste regio uit tabel 1 ingevoerd, Oost-Groningen respectievelijk Flevoland. En we hoeven deze berekening natuurlijk niet handmatig uit te voeren, dat doet statistische software zoals SPSS of R vliegensvlug voor ons. In het analysebestand is slechts één regel Pythoncode eraan gewijd.)
De correlatiecoëfficiënt is 0,91. Verwijzend naar tabel 2 houdt dit een zeer sterke samenhang tussen inkomen en huizenprijs in. Dit wordt bevestigd door het spreidingsdiagram in figuur 3, waar de punten dicht bij een denkbeeldige opwaartse rechte lijn liggen. In regio’s met een laag gemiddeld inkomen ligt de gemiddelde huizenprijs laag, zoals Delfzijl en Oost-Groningen. Daarentegen ligt in regio’s met een hoog gemiddeld inkomen de gemiddelde huizenprijs hoog, zoals Haarlem en Het Gooi en Vechtstreek. Let op, het maakt niet uit welke van de twee variabele we als x of als y nemen. De correlatiecoëfficiënt blijft exact hetzelfde, ook al zouden in tabel 1 de kolommen (en in figuur 3 de assen) “Inkomen” en “Huizenprijs” zijn omgewisseld. Bovendien moeten we ervoor waken om niet de kapitale blunder te begaan door te concluderen: “hoge huizenprijzen worden veroorzaakt door hoge inkomens”, waarover later meer.
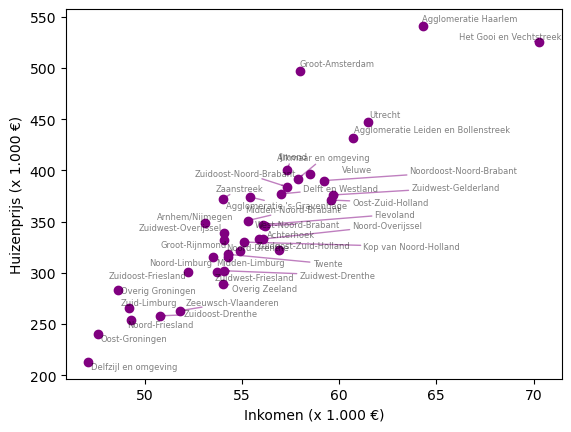
Figuur 3. Scatterplot dat de samenhang tussen inkomen (x) en huizenprijs (y) verduidelijkt. Door uitsluitend naar tabel 1 te kijken is deze samenhang niet direct zichtbaar.
Door de correlatiecoëfficiënt te kwadrateren verkrijgen we de zogenaamde correlatiedeterminant (R2, ook wel de proportie verklaarde variantie genoemd). Dit getal, dat uitgedrukt wordt als percentage, is een maat waarmee de variatie in de ene variabele verklaard wordt door de andere variabele. Het dient als indicator voor de sterkte van de samenhang. In ons voorbeeld wordt de correlatiedeterminant als volgt berekend: \[R^2={0,91}^2\approx0,82\]Dit wil zeggen dat 82% van de variantie in huizenprijzen kan worden toegeschreven aan het gebruik van inkomens als voorspeller van die huizenprijzen.
Het is wenselijk om op basis van een willekeurige waarde van de ene variabele (de criteriumvariabele of onafhankelijke variabele, die gewoonlijk op de x-as staat) een voorspelling te kunnen doen over de waarde van de andere variabele (de predictorvariabele of afhankelijke variabele, die gewoonlijk op de y-as staat). Deze mogelijkheid wordt geboden door een methode genaamd lineaire regressie, die hier niet uit de doeken wordt gedaan, waarin een best passende rechte lijn door de datapunten in het spreidingsdiagram getrokken wordt. Door de gekozen waarde van de criteriumvariabele in te vullen in de formule die deze regressielijn beschrijft, wordt de verwachte waarde van de predictorvariabele verkregen.
In de meeste voorbeelden die in dit artikel aan bod zijn gekomen ligt een oorzakelijk verband ten grondslag (groeien leidt tot gewichtstoename, langer slapen leidt tot minder gapen). Dat is niet zonder meer het geval. Hoewel een sterke correlatie kan zijn vastgesteld, kan men enkel uit dit gegeven geen causaliteit afleiden! Correlationeel onderzoek kan weliswaar erg nuttig zijn, maar zulke observationele studies alleen bieden onvoldoende gronden om claims van oorzaak-gevolg te maken. Daarvoor zijn aanvullende experimenten nodig die de richting van een effect blootleggen of uitsluiten, het welbekende gerandomiseerde gecontroleerde onderzoek (randomised controlled trial, afgekort RCT). Met andere woorden: indien twee variabelen met elkaar samenhangen wil dat niet zomaar zeggen dat de ene variabele door de andere variabele wordt veroorzaakt.
Neem de relatie tussen lichaamsbeweging en depressiviteit (r = -0,107).7 Zorgt minder bewegen ervoor dat iemand meer depressieve klachten ervaart, of zorgen meer depressieve klachten ervoor dat iemand minder beweegt? De richting is niet eenduidig en beide hypothesen zijn plausibel. Een alternatieve mogelijke verklaring is dat een derde factor (een zogenaamde confounding variable), zoals voeding, een rol speelt en “achter de schermen” invloed uitoefent op zowel lichaamsbeweging als depressiviteit. Je zou kunnen inbeelden dat een individu dat te weinig eet en drinkt niet de energie heeft om te gaan sporten, en tegelijkertijd gevoelens van neerslachtigheid ontwikkelt omdat hij te weinig voedingsstoffen tot zich neemt (zie figuur 4).
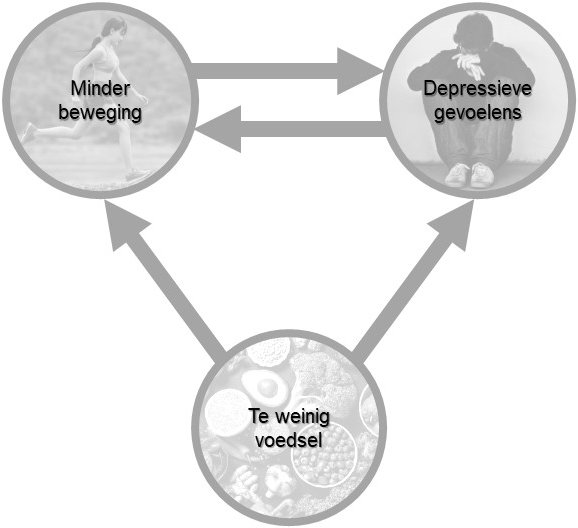
Figuur 4. Potentiële interacties tussen lichaamsbeweging, depressie en voeding.
Achtergrondafbeeldingen bewerkt onder een CC BY-NC 4.0 licentie.
Analoog aan dit voorbeeld kunnen we niet met zekerheid stellen dat hogere salarissen tot hogere huizenprijzen leiden. Wellicht zorgt de villa die iemand betrekt ervoor dat zij in welgestelde sociale kringen verkeert, en de royaal betaalde functies voor het uitkiezen heeft. Het is net zo aannemelijk dat een derde variabele, bijv. economische groei, zowel de salarissen als de huizenprijzen opdrijft.
“Zo” is derhalve niet noodzakelijkerwijs terug te voeren op “zus”. Dat wél doen is een van de meest gemaakte fouten bij het interpreteren van statistische resultaten, hetzij door studenten, journalisten, politici of nota bene wetenschappers. De schrijver en econoom Thomas Sowell beschreef deze valkuil ad rem: “Een van de eerste dingen die in lesboeken over statistiek worden uitgelegd, is het verschil tussen correlatie en causaliteit. Het is ook een van de eerste dingen die mensen weer vergeten.”8 Dus mocht je op kantoor, aan de keukentafel of in de kroeg op een bewering stuiten die stelt dat eigenschap A voortvloeit uit eigenschap B omdat ze nauw met elkaar geassocieerd zijn, herinner dan dat correlatie niet per se causaliteit impliceert.
Er zijn voorbeelden te over van situaties waarin zulke onterechte oorzakelijke verbanden worden gelegd. De meest kwalijke is misschien wel die tussen vaccinaties en autisme. Hier wordt de suggestie gewekt dat inentingen symptomen van autisme teweegbrengen. Op social media wordt deze bewering – helaas – nog steeds door menigeen aangehangen. De impuls die deze dwaling in gang zette was een publicatie uit 1998 in het medische tijdschrift The Lancet.9 Uit dit onderzoek onder twaalf kinderen concludeerden de Britse arts Andrew Wakefield en consorten dat het vaccin tegen mazelen, dat kleine hoeveelheden virusdeeltjes bevat, de darmen en hersenen aantast. Daardoor zouden kinderen autistische trekken gaan vertonen, een aandoening die hij “autistic enterocolitis” noemde. Inmiddels hebben tal van studies deze bewering ontkracht; er is geen verband tussen gevaccineerd worden en het ontwikkelen van autisme.10 Het paper werd in 2010 ingetrokken. Het idee dat vaccinaties autisme veroorzaakt blijft ondertussen rondzweven in de ether.
Om bovenstaande misvatting voorgoed de wereld uit te helpen: er is een derde onderliggende variabele werkzaam, dat is leeftijd. Rond het derde levensjaar krijgt een kind de BMR-prik, precies de leeftijd waarop autisme wordt gediagnostiseerd.11,12 Een ongetraind oog legt meteen een link tussen de twee variabelen. Wakefield kon niet bevroeden welke langdurige, negatieve consequenties zijn bedrog zouden hebben. Desondanks had hij als dokter beter moeten weten. Toentertijd paste hij uit financiële belangen patiëntgegevens van proefpersonen aan. Kortom: een casus van regelrechte fraude. Dit verhaal illustreert hoe een gebrek aan statistische bekwaamheid bij de doorsnee social media-gebruiker schadelijke effecten voor de samenleving tot gevolg kan hebben. Ouders laten hun kroost niet vaccineren waardoor zij (en andere peuters) onnodig risico lopen om ziek te worden.
Gelukkig zijn niet alle spurieuze correlaties, zoals deze onterechte verbanden genoemd worden, even ernstig. Een komisch verband is die tussen het aantal succesvolle beklimmingen van Mount Everest en het aantal hot-dogs gegeten door de kampioen van “Nathan’s Hot Dog Eating Competition” (r = 0,926).13 Of wat te denken van de relatie tussen de afstand van Uranus tot de maan en de hoeveelheid opgewekte elektriciteit in Japan (r = 0,985).14 Iedereen zal begrijpen dat de relatie tussen de genoemde variabelen volstrekt ridicuul is. Redenen voor de aanwezigheid van een spurieuze correlatie kunnen zijn: een te kleine steekproef, observaties die afhankelijk zijn van elkaar of de aanwezigheid van uitbijters. Tot slot geldt dat wanneer je verschillende datasets combineert tot reusachtige datasets en maar lang genoeg blijft zoeken naar verbanden, je deze vanzelf zal vinden. (Dit noemt men data dredging.) Zelfs al zijn ze niet valide.
1. Centraal Bureau voor de Statistiek (CBS). (20 februari 2024). Gemiddelde transactieprijs koopwoning in 2023 ruim 416 duizend euro. https://www.cbs.nl/nl-nl/nieuws/2024/08/gemiddelde-transactieprijs-koopwoning-in-2023-ruim-416-duizend-euro
2. Centraal Planbureau (CPB). (26 februari 2025). Centraal Economisch Plan 2025. https://www.cpb.nl/cep-2025-cijfers
3. De Hypotheker. (Geraadpleegd op 14 december 2025). Maximale hypotheek berekenen. https://www.hypotheker.nl/zelf-berekenen/hoeveel-kan-ik-lenen/
4. Centraal Bureau voor de Statistiek (CBS). (21 januari 2010). COROP-gebieden. https://www.cbs.nl/nl-nl/achtergrond/2010/03/corop-gebieden
5. Moore, D.S., & McCabe, G.P. (2006). Introduction to the Practice of Statistics (5th ed.). USA: W.H. Freeman and Company.
6. Wikipedia, The Free Encyclopedia. (2025, December 18). Correlation coefficient. https://en.wikipedia.org/wiki/Correlation_coefficient
7. Li, S., Wang, X., Wang, P., Qiu, S., Xin, X., Wang, J., Zhao, J., & Zhou, X. (2023). Correlation of exercise participation, behavioral inhibition and activation systems, and depressive symptoms in college students. Scientific Reports, 13(16460), 1-9. DOI: https://doi.org/10.1038/s41598-023-43765-9
8. Sowell, T. (1995). The vision of the anointed: Self-congratulation as a basis for social policy. New York: Basic Books.
9. Wakefield, A.J., Murch, S.H., Anthony, A., Linnell, J., Casson, D.M., Malik, M., Berelowitz, M., Dhillon, A.P., Thomson, M.A., Harvey, P., Valentine, A., Davies, S.E., & Walker-Smith, J.A. (1998). RETRACTED: Ileal-lymphoid-nodular hyperplasia, non-specific colitis, and pervasive developmental disorder in children. The Lancet, 351(9103), 637-641. DOI: https://doi.org/10.1016/s0140-6736(97)11096-0 (Intrekking gepubliceerd in 2010, The Lancet, 375(9713), 445)
10. Ritchie, S. (2021). Science Fictions: Exposing Fraud, Bias, Negligence and Hype in Science. Great Britain: Vintage.
11. Rijksinstituut voor Volksgezondheid en Milieu. (Geraadpleegd op 10 januari 2026). Vaccinatieschema. https://rijksvaccinatieprogramma.nl/vaccinaties/vaccinatieschema
12. Steiner, A. M., Goldsmith, T. R., Snow, A. V., & Chawarska, K. (2012). Practitioner’s guide to assessment of autism spectrum disorders in infants and toddlers. Journal of Autism and Developmental Disorders, 42(6), 1183-1196. DOI: https://doi.org/10.1007/s10803-011-1376-9
13. Vigen, T. (Jan 2024). Total Number of Successful Mount Everest Climbs correlates with Hotdogs consumed by Nathan’s Hot Dog Eating Competition Champion. Spurious Correlations. https://tylervigen.com/spurious/correlation/1159_total-number-of-successful-mount-everest-climbs_correlates-with_hotdogs-consumed-by-nathans-hot-dog-eating-competition-champion
14. Vigen, T. (2024). The distance between Uranus and the moon correlates with Electricity generation in Japan. Spurious Correlations. https://tylervigen.com/spurious/correlation/2730_the-distance-between-uranus-and-the-moon_correlates-with_electricity-generation-in-japan